𝗣𝗘𝗥𝗣𝗟𝗘𝗫𝗜𝗧𝗬🇦 🇮
Perplexity
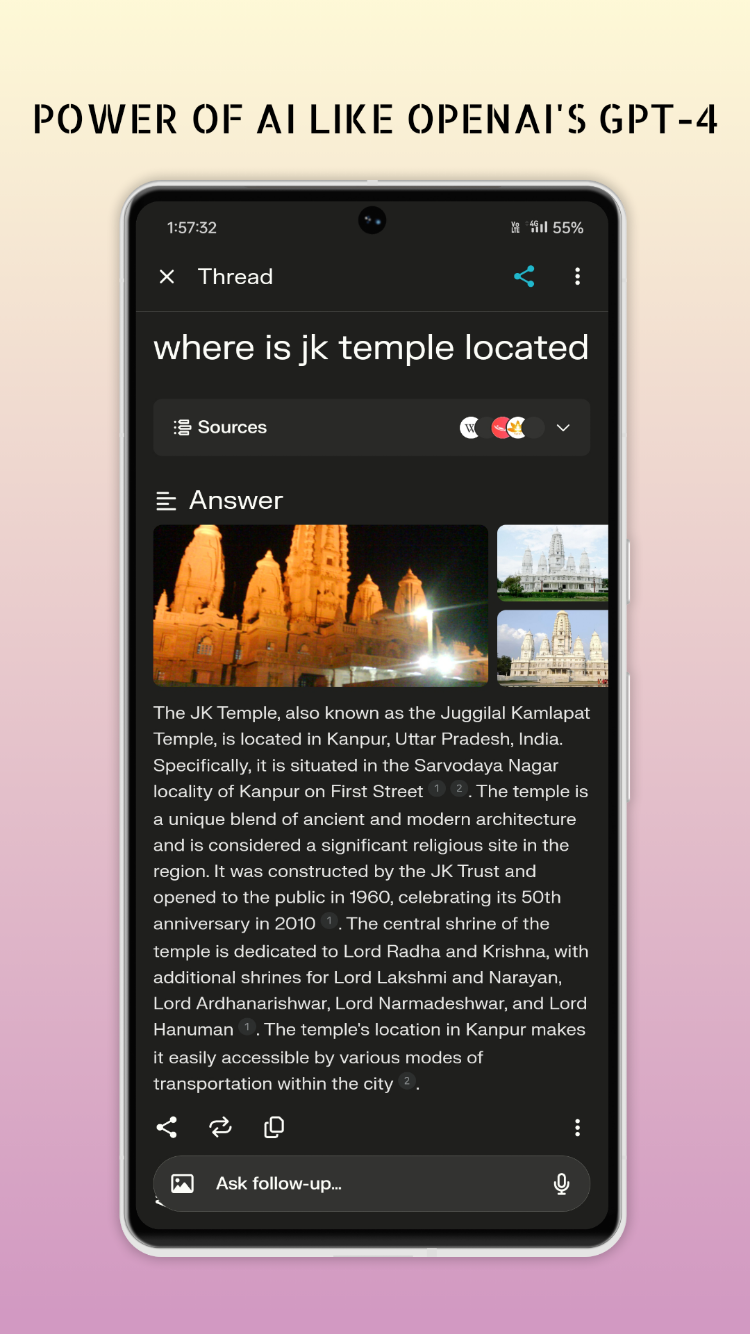
The most powerful answer engine powered by AI.
Perplexity—Where Knowledge Begins. The answers you need—right at your finger tips.
Cut through the clutter and get straight to credible, up-to-date answers. This free app syncs across devices and leverages the power of AI like OpenAI’s GPT-4 and Anthropic’s Claude 2. Your smarter way to know and understand.
Features:
· Perplexity Copilot: Guided AI search for deeper exploration.
· Ask with voice or text: Instant, up-to-date answers whether you type or say it.
· Thread Follow-Up: Keep the conversation going for a deeper understanding.
· Trust Built In: Cited sources for every answer.
· Discover: Learn new things from the community.
· Your Library: More than search history, it’s a curation of your discoveries.
Perplexity, in information theory, is a measure of uncertainty in a sample from a discrete probability distribution. It quantifies how well a probability model predicts a sample, with higher perplexity indicating greater uncertainty in predicting the value drawn from the distribution. Perplexity is widely used in information theory, machine learning, and statistical modeling to assess the performance of language models and evaluate the uncertainty or “surprise” related to outcomes. It is calculated based on the entropy of the distribution, representing the average number of bits needed to encode the information in a random variable. In natural language processing, perplexity is a key metric for evaluating language models, reflecting their ability to predict among a set of specified tokens. The concept of perplexity helps in understanding the level of uncertainty in predictions and the effectiveness of models in capturing the underlying distribution of data